
Do LLMs Actually Continuously Learn? The Reality of Frozen Models and Dynamic AI Systems
David Iroaganachi
6/9/20264 min read
Do LLMs actually continuously learn, or is this something we only think they do? This is an important question because the phrase “continuous learning” is often used loosely when people talk about large LLMs and generative AI. I have seen this come up in discussions around AI use in life sciences, especially among CSV, QA, Quality IT, and other professionals.
For regulated teams, this distinction matters. If we misunderstand how an LLM behaves, we may also misunderstand the risks, controls, audit expectations, and validation and implementation approach needed around the system.
At this point, many people understand that most LLMs are trained up to a certain point in time. The result of that training is then fixed into the model, and the model is deployed.
But the part that is often overlooked is this: after deployment, your day-to-day prompts do not usually keep updating the model’s training data or internal weights. Basically, the information you type into the model may be used to answer you in that moment, but it is not automatically being written back into the model as new training.
So why does it look like they are learning?
What we assume vs what actually happens
The common assumption
“If we keep using the LLM, it will get smarter.”
“If users keep entering company data, the model will continue learning from that data.”
These assumptions are understandable, especially in life science regulated environments where system behaviour, data control, auditability, and change control matter.
The reality: a frozen core
In reality:
The model is trained offline on a very large dataset up to a specific cut‑off date.
That training run produces a set of parameters (weights).
Those weights are then frozen and deployed as “Model Version X.”
Once that model version is in production, it does not automatically keep absorbing new knowledge from your prompts. To change what the model “knows,” the vendor has to run another training or fine‑tuning job and release a new version.
This is why model versioning becomes important. If the model changes, teams need to know what version is being used, when it changed, and whether that change affects the intended use of the system.
So, in simple terms, your prompts and your data are inputs to the model during that interaction. They are not usually live training material being written back into the model in real time.
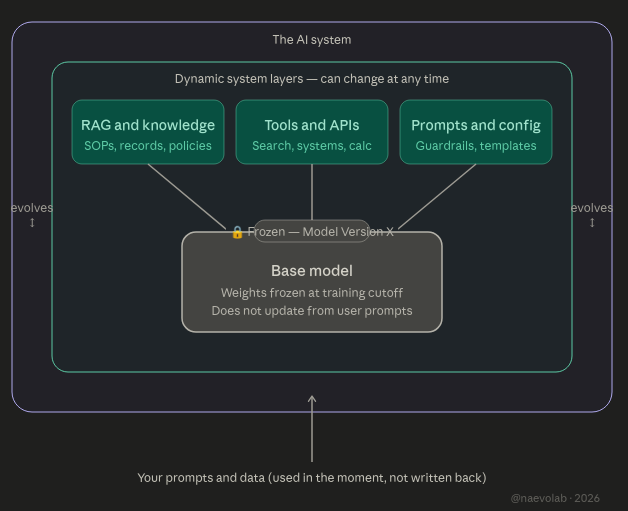
Why it looks like continuous learning: the system around the model
Even if the base model is frozen, everything around it can be very dynamic. That is where the impression of continuous learning comes from.
Typical moving parts:
APIs and tools: The LLM is wired to various tools (DMS, QMS, controlled knowledge base). As those tools evolve, the overall system behaves differently, even though the core model hasn’t changed.
Databases and knowledge stores: Many solutions use retrieval‑augmented generation (RAG) or similar patterns. New SOPs, policies or records are added to a database, and the LLM retrieves them at runtime.
Configuration and prompts: Prompt templates, guardrails and business logic are refined over time. Better prompts and better orchestration make the system seem smarter.
From the user’s perspective, we see an AI assistant that improves over time.
But in many cases, what is actually changing is:
the data the system can retrieve,
the tools the system can call,
the prompts or instructions used to guide it,
or the workflow around the model.
The model itself may still be the same fixed model version.
A concrete GPT-style example
Take a hosted GPT-like service as an example.
Some hosted GPT-like services can remember details from past interactions or data you have provided (it can usually be switched off). That information can be reused as context in future conversations, making it seem like the model has learned about you.
But that is not the same as the base model being retrained.
What is usually happening is simpler:
user history or preferences may be stored in a database,
relevant information may be added back into the next prompt,
the model uses that context to respond,
but the model weights are not being rewritten in real time.
So the system may be remembering and reusing information, but the model itself is not continuously learning the system around it is remembering.
Why this matters for regulated and validated systems
You may be controlling an evolving system
Even with a frozen model, the system around it can still change:
data sources and RAG content,
prompt templates,
guardrail rules and policies,
connected tools and APIs.
Those changes can materially affect system behaviour, so they should be considered within your change control and validation approach.
For example:
Updating a knowledge base is more like changing a controlled data source than training a model.
Updating prompts and orchestration is more like changing business rules or workflow logic.
Adding or removing tools is more like changing integrations or interfaces.
Understanding this helps you put the right type of control on each layer, instead of treating everything as “the model.”
It helps you ask better questions of vendors and internal teams
Once you are clear that models do not usually learn continuously during normal use, you can ask more precise questions:
Does this system use a fixed base model, or can the model weights update in production?
How often are new model versions released, and how are those changes communicated?
Which components can change without a new model release, such as RAG content, prompts, tools, or guardrails?
What happens when a new model version is released?
Conclusion
Understanding that LLMs generally operate with frozen weights after deployment is essential for effective governance in regulated industries.While the base model itself does not continuously learn from user interactions, the broader ecosystem around it, including retrieval databases, tool integrations, and prompt configurations, can remain highly dynamic.
This distinction shifts the focus from monitoring “continuous model learning” to managing system components through appropriate change control and versioning.